
The purpose of this page is to provide details for the various types of errors and failures that can arise during message processing. A set of rules that every Worker implementation should adhere to is included as well.
We start though by describing the expected flow when messages are handled by Worker implementations without any issues at all.
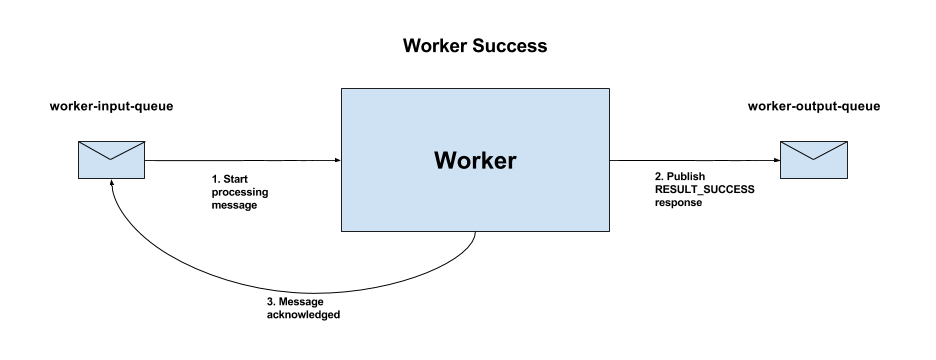 Figure 1 - Message successfully processed by Worker
Figure 1 - Message successfully processed by Worker
worker-input-queue and will start to process it.RESULT_SUCCESS response is published on the messaging output queue, worker-output-queue by the worker framework.Some messages however cannot be handled by the Worker and these are described next.
A poisoned message is a message that a worker is unable to handle. The message is deemed poisonous during processing when repeated catastrophic failure of the worker occurs. Regardless of how many times the message is retried, the worker will not be able to handle the message in a graceful manner. The flow of a poisoned message is described in Figure 2 below:
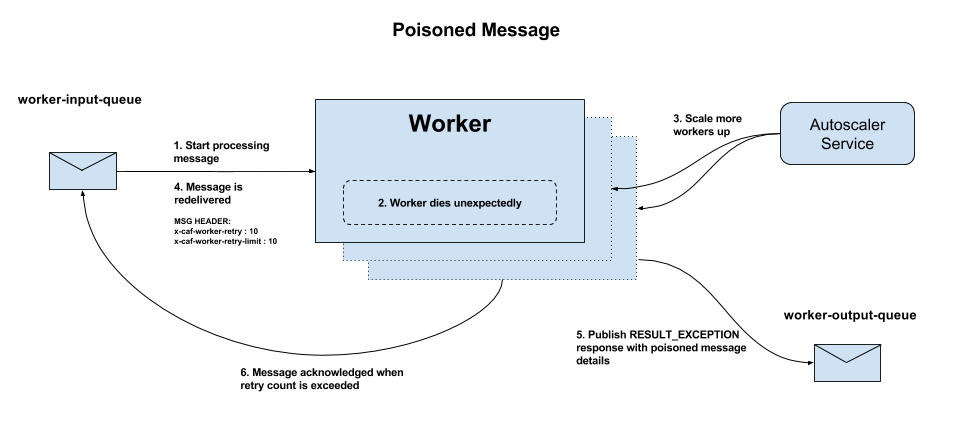 Figure 2 - Classic Queue Poisoned message flow
Figure 2 - Classic Queue Poisoned message flow
worker-input-queue and will start to process it.x-caf-worker-retry message header is stamped on the message and incremented. Messages which cause a worker to crash are retried up to 10 times by default before the worker gives up trying to process them and marks them as poisoned. Note that the number of permitted retries is configurable via the environment variable CAF_WORKER_RETRY_LIMIT.RESULT_EXCEPTION response including the poisoned message details is published on the messaging output queue worker-output-queue by the worker framework. The poison message details will contain the worker friendly name defined using environment variable CAF_WORKER_FRIENDLY_NAME. Setting CAF_WORKER_FRIENDLY_NAME for the worker is preferable. If not set, the worker friendly name will default to the worker class name.With Quorum Queues the number of delivery attempts is supplied in a header x-delivery-count. This removes the need for
x-caf-worker-retry to be managed by the framework and messages republished with an updated x-caf-worker-retry
header.
Messages which cause OutOfMemory / StackOverflow errors also cause the Worker to crash. These are treated the same as poisoned messages and will be retried until successful or until the retry count exceeds the permitted number of retries. If the permitted number of retries is exceeded the message will be placed on the worker-output-queue by the framework, with a task status of RESULT_EXCEPTION. See Figure 2 above for further details.
Transient errors arise as a result of a failure beyond the control of the Worker, e.g the database being down or unavailable.
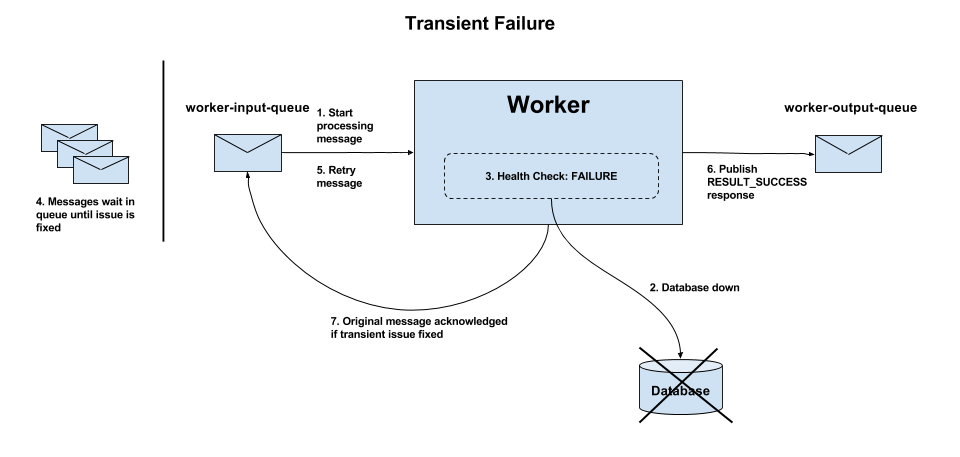 Figure 3 - Transient failure flow
Figure 3 - Transient failure flow
worker-input-queue and will start to process it.RESULT_SUCCESS response is placed on the messaging output queue worker-output-queue by the worker framework.An InvalidTaskException is thrown when the input message is not parsable. This exception type does not cause the Worker to crash. The message is never re-tried. Instead, an INVALID_TASK response with error details is placed on the messaging output queue worker-output-queue by the worker framework.
A RuntimeException can be detected by the Worker as a result of some fault in the Worker logic (e.g. NullPointerException). The Worker will not crash as a result of this kind of error but the original message will never be retried.
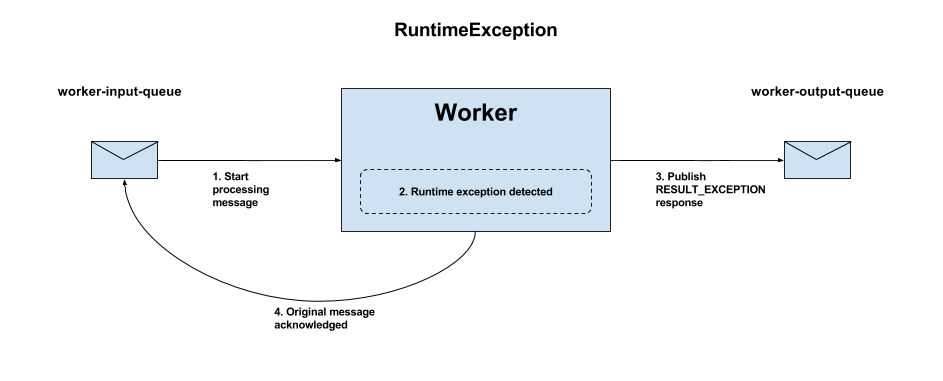 Figure 4 - RuntimeException flow
Figure 4 - RuntimeException flow
worker-input-queue and will start to process it.RESULT_EXCEPTION response with exception details is placed on the messaging output queue worker-output-queue by the worker framework.The general following rules should be adhered to by all Worker implementations:
The WorkerFactory should identify whether the task message data is
parsable and this is the first opportunity to throw an InvalidTaskException.
Once a Worker is created with a task object, the framework will verify the
object’s constraints (if there are any), which is the second chance to throw
InvalidTaskException. The constructor of the Worker can throw an
InvalidTaskException. Finally a worker’s doWork() method can thow an
InvalidTaskException.
While InvalidTaskException is a non-retryable case, there may be retryable
scenarios for instance a brief disconnection from a temporary resources such as
a database. If you have a health check in your WorkerFactory and this is
currently failing, you may wish to throw TaskRejectedException, which will
push the task back onto the queue. Once inside a Worker itself, either the
code or the libraries used should be able to tolerate some amount of transient
failures in connected resources, but if this still cannot be rectified in a
reasonable time frame then it is also valid to throw TaskRejectedException from
inside the Worker, with the understanding that any amount of work done so
far will be abandoned.
You do not need to handle the following, as the framework will handle it: